



































Kimi k1.5: A Next Generation Multi-Modal LLM Trained with Reinforcement Learning on Advancing AI with Scalable Multimodal Reasoning and Benchmark Excellence
Reinforcement learning (RL) has fundamentally transformed AI by allowing models to improve performance iteratively through interaction and feedback. When applied to large language models (LLMs), RL opens new avenues for handling tasks that require complex reasoning, such as mathematical problem-solving, coding, and multimodal data interpretation. Traditional methods rely heavily on pretraining with large static datasets. […] The post Kimi k1.5: A Next Generation Multi-Modal LLM Trained with Reinforcement Learning on Advancing AI with Scalable Multimodal Reasoning and Benchmark Excellence appeared first on MarkTechPost.



Reinforcement learning (RL) has fundamentally transformed AI by allowing models to improve performance iteratively through interaction and feedback. When applied to large language models (LLMs), RL opens new avenues for handling tasks that require complex reasoning, such as mathematical problem-solving, coding, and multimodal data interpretation. Traditional methods rely heavily on pretraining with large static datasets. Still, their limitations have become evident as models solve problems that require dynamic exploration and adaptive decision-making.
A main challenge in advancing LLMs lies in scaling their capabilities while ensuring computational efficiency. Based on static datasets, conventional pretraining approaches struggle to meet the demands of complex tasks involving intricate reasoning. Also, existing LLM RL implementations have failed to deliver state-of-the-art results due to inefficiencies in prompt design, policy optimization, and data handling. These shortcomings have left a gap in developing models capable of performing well across diverse benchmarks, especially those requiring simultaneous reasoning over text and visual inputs. Solving this problem necessitates a comprehensive framework that aligns model optimization with task-specific requirements while maintaining token efficiency.
Prior solutions for improving LLMs include supervised fine-tuning and advanced reasoning techniques such as chain-of-thought (CoT) prompting. CoT reasoning allows models to break down problems into intermediate steps, enhancing their ability to tackle complex questions. However, this method is computationally expensive and often constrained by traditional LLMs’ limited context window size. Similarly, Monte Carlo tree search, a popular technique for reasoning enhancement, introduces additional computational overhead and complexity. The absence of scalable RL frameworks for LLMs has further restricted progress, underscoring the need for a novel approach that balances performance improvements with efficiency.
Researchers from the Kimi Team have introduced Kimi k1.5, a next-generation multimodal LLM designed to overcome these challenges by integrating RL with extended context capabilities. This model employs innovative techniques such as long-context scaling, which expands the context window to 128,000 tokens, enabling it to process larger problem contexts effectively. Unlike prior approaches, the Kimi k1.5 avoids relying on complex methods like Monte Carlo tree search or value functions, opting for a streamlined RL framework. The research team implemented advanced RL prompt set curation to enhance the model’s adaptability, including diverse prompts spanning STEM, coding, and general reasoning tasks.
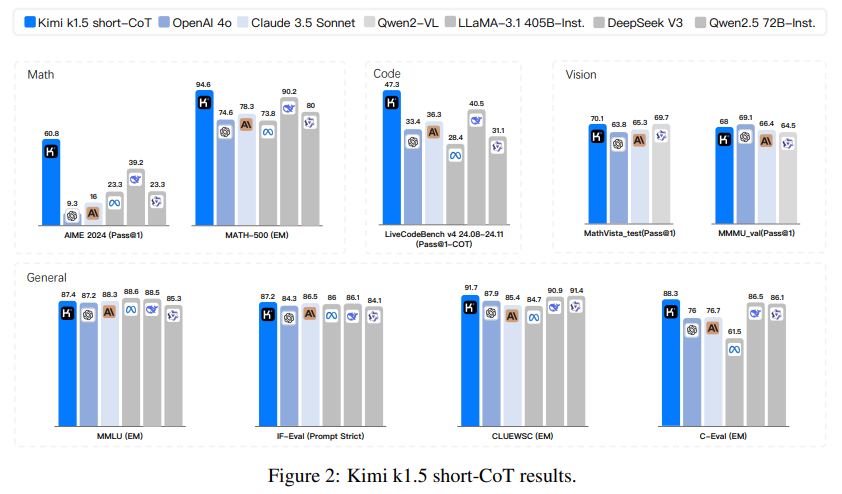
The Kimi k1.5 was developed in two versions:
- The long-CoT model: It excels in extended reasoning tasks, leveraging its 128k-token context window to achieve groundbreaking results across benchmarks. For instance, it scored 96.2% on MATH500 and 94th percentile on Codeforces, demonstrating its ability to handle complex, multi-step problems.
- The short-CoT model: The short-CoT model was optimized for efficiency using advanced long-to-short context training methods. This approach successfully transferred reasoning priors from the long-CoT model, allowing the short-CoT model to maintain high performance, 60.8% on AIME and 94.6% on MATH500, while significantly reducing token usage.
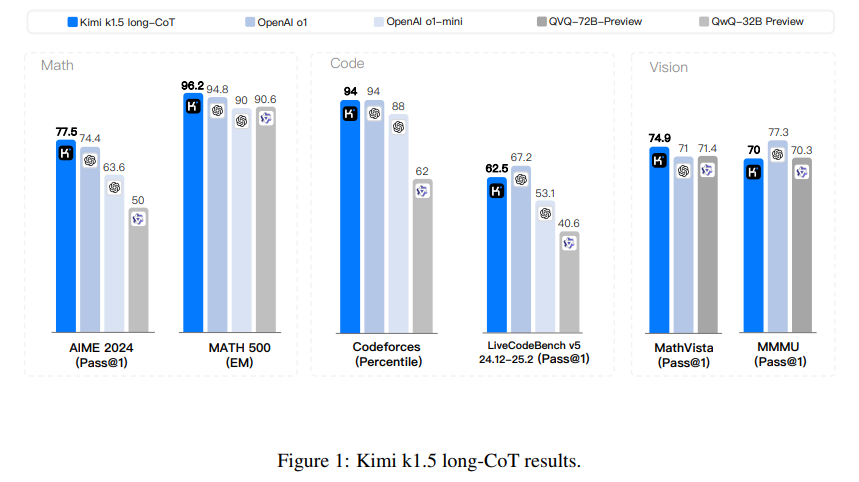
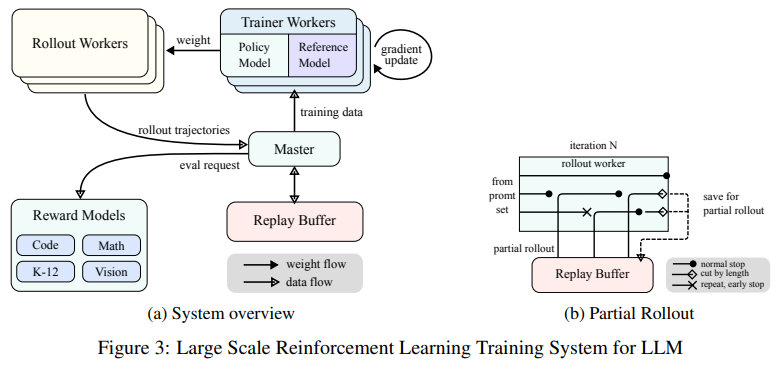
The training process combined supervised fine-tuning, long-chain reasoning, and RL to create a robust framework for problem-solving. Key innovations included partial rollouts, a technique that reuses previously computed trajectories to improve computational efficiency during long-context processing. Using multimodal data sources, such as real-world and synthetic visual reasoning datasets, further strengthened the model’s ability to interpret and reason across text and images. Advanced sampling strategies, including curriculum and prioritized sampling, ensured training focused on areas where the model demonstrated weaker performance.
Kimi k1.5 demonstrated significant improvements in token efficiency through its long-to-short context training methodology, enabling the transfer of reasoning priors from long-context models to shorter models while maintaining high performance and reducing token consumption. The model achieved exceptional results across multiple benchmarks, including a 96.2% exact match accuracy on MATH500, a 94th percentile on Codeforces, and a pass rate of 77.5% on AIME, surpassing state-of-the-art models like GPT-4o and Claude Sonnet 3.5 by substantial margins. Its short-CoT performance outperformed GPT-4o and Claude Sonnet 3.5 on benchmarks like AIME and LiveCodeBench by up to 550%, while its long-CoT performance matched o1 across multiple modalities, including MathVista and Codeforces. Key features include long-context scaling with RL using context windows of up to 128k tokens, efficient training through partial rollouts, improved policy optimization via online mirror descent, advanced sampling strategies, and length penalties. Also, Kimi k1.5 excels in joint reasoning over text and vision, highlighting its multi-modal capabilities.
The research presented several key takeaways:
- By enabling models to explore dynamically with rewards, RL removes the constraints of static datasets, expanding the scope of reasoning and problem-solving.
- Using a 128,000-token context window allowed the model to effectively perform long-chain reasoning, a critical factor in its state-of-the-art results.
- Partial rollouts and prioritized sampling strategies optimized the training process, ensuring resources were allocated to the most impactful areas.
- Incorporating diverse visual and textual data enabled the model to excel across benchmarks requiring simultaneous reasoning over multiple input types.
- The streamlined RL framework used in Kimi k1.5 avoided the pitfalls of more computationally demanding techniques, achieving high performance without excessive resource consumption.
In conclusion, the Kimi k1.5 addresses the limitations of traditional pretraining methods and implements innovative techniques for context scaling and token efficiency; the research sets a new benchmark for performance across reasoning and multimodal tasks. The long-CoT and short-CoT models collectively showcase the adaptability of Kimi k1.5, from handling complex, extended reasoning tasks to achieving token-efficient solutions for shorter contexts.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.

What's Your Reaction?














