





































Simplicity Over Black Boxes
Turning complex ML models into simple, interpretable rules with Human Knowledge Models for actionable insights and easy inferenceCover, image by AuthorModern machine learning has delivered incredible breakthroughs in lots of fields. These successes come from advanced models that can uncover intricate patterns in massive datasets.But there’s one area where this approach falls short: easy interpretation. Most ML models, often referred to as “black boxes,” take vast amounts of data and contain thousands of coefficients and weights. Instead of extracting clear, actionable insights, they leave us with results that are difficult for humans to understand or apply.This gap highlights the need for a different approach — one that focuses on finding concise, interpretable rules rather than relying solely on complex models.Most efforts focus on explaining “black box” models rather than directly extracting knowledge from raw data. The root of the problem lies in the “machine-first” mindset, where the priority is building optimal algorithms rather than human-like knowledge extraction. Humans rely on knowledge to generate experiments and new data, but the reverse — converting data into actionable knowledge — is largely overlooked.The quest to turn complex data into simple, human-understandable logic has been around for decades. Starting in the 1960s, research on formal logic inspired the creation of rule-learning algorithms like Corels, RuleFit, and Skope-Rules. These methods extract concise Boolean expressions from complex data, often using greedy optimization techniques. However, despite progress in interpretable and explainable AI, significant challenges remain.Not a long time ago a group of scientists from Russia and France suggested their approach — Human Knowledge Models (HKM), which distill data into the form of simple rules.HKM creates simple rules that contain basic Boolean operators (AND, OR, NOT) and thresholds. It comes up not more than with 4 rules. These rules are easy to use in different domaines, especially when a human is involved.When you may want to use this:predictions will be used by field experts. For instance, a doctor might receive a model’s prediction about the likelihood of a patient having pneumonia. If the prediction comes from a “black box,” it becomes challenging for the doctor to adjust the results based on personal experience, leading to low trust in such predictions. A more effective approach would be to distill clear, understandable rules from patient medical histories (e.g., “If the patient’s blood pressure is above 120 and their temperature exceeds 38°C, the risk of pneumonia is high”).When deploying an ML model to production is unjustifiably expensive or complex, a few business rules can often be implemented more easily, even directly on the front-end.When you have small number of features or observations and can’t build a complex model.HKM trainingThe HKM training identifies:thresholds to simplify continuous data;the best subset of features;the optimal Boolean logic to model decision-making.The process generates all possible Boolean functions, simplifies them into concise formulas, and evaluates their performance. Unlike traditional machine learning, which adjusts coefficients, HKMs explore different combinations of features and rules to find the most effective yet human-comprehensible models.Training process, image by AuthorHKM training avoids imputing missing data, treating it as valuable information, and produces multiple top-performing models, giving users flexibility in choosing the most practical solution.Where HKMs Fall ShortHKMs aren’t suited for every problem. For tasks with high branching complexity (big number of features) their simplicity becomes a disadvantage. These scenarios require substantial memory and logic that exceed human processing capacity. Nonetheless, HKMs can still play a critical role in applied fields like healthcare, where they serve as a practical starting point to address obvious blind spots.Another limitation lies in feature identification. Unlike deep-learning models that can automatically extract complex patterns, HKMs depend on humans to define and measure key features. That’s why feature engineering falls on the shoulders of the analyst.Churn prediction exampleAs a toy example we will use a generated Churn prediction dataset.Install the libraries:!pip install git+https://github.com/EgorDudyrev/PeaViner!pip install bitarrayDataset generation:import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import f1_scorenp.random.seed(42)n_rows = 1500charge_amount = np.random.normal(10, np.sqrt(2), n_rows).astype(int)seconds_of_use = np.random.gamma(shape=2, scale=2500, size=n_rows).astype(int)frequency_of_use = np.random.normal(20, np.sqrt(10), n_rows).astype(int)tariff_plan = np.random.choice([1, 2], size=n_rows) status = np.random.choice([2, 3], size=n_rows) age = np.random.randint(20, 71, size=n_rows) noise = np.random
Turning complex ML models into simple, interpretable rules with Human Knowledge Models for actionable insights and easy inference
Modern machine learning has delivered incredible breakthroughs in lots of fields. These successes come from advanced models that can uncover intricate patterns in massive datasets.
But there’s one area where this approach falls short: easy interpretation. Most ML models, often referred to as “black boxes,” take vast amounts of data and contain thousands of coefficients and weights. Instead of extracting clear, actionable insights, they leave us with results that are difficult for humans to understand or apply.
This gap highlights the need for a different approach — one that focuses on finding concise, interpretable rules rather than relying solely on complex models.
Most efforts focus on explaining “black box” models rather than directly extracting knowledge from raw data. The root of the problem lies in the “machine-first” mindset, where the priority is building optimal algorithms rather than human-like knowledge extraction. Humans rely on knowledge to generate experiments and new data, but the reverse — converting data into actionable knowledge — is largely overlooked.
The quest to turn complex data into simple, human-understandable logic has been around for decades. Starting in the 1960s, research on formal logic inspired the creation of rule-learning algorithms like Corels, RuleFit, and Skope-Rules. These methods extract concise Boolean expressions from complex data, often using greedy optimization techniques. However, despite progress in interpretable and explainable AI, significant challenges remain.
Not a long time ago a group of scientists from Russia and France suggested their approach — Human Knowledge Models (HKM), which distill data into the form of simple rules.
HKM creates simple rules that contain basic Boolean operators (AND, OR, NOT) and thresholds. It comes up not more than with 4 rules. These rules are easy to use in different domaines, especially when a human is involved.
When you may want to use this:
- predictions will be used by field experts. For instance, a doctor might receive a model’s prediction about the likelihood of a patient having pneumonia. If the prediction comes from a “black box,” it becomes challenging for the doctor to adjust the results based on personal experience, leading to low trust in such predictions. A more effective approach would be to distill clear, understandable rules from patient medical histories (e.g., “If the patient’s blood pressure is above 120 and their temperature exceeds 38°C, the risk of pneumonia is high”).
- When deploying an ML model to production is unjustifiably expensive or complex, a few business rules can often be implemented more easily, even directly on the front-end.
- When you have small number of features or observations and can’t build a complex model.
HKM training
The HKM training identifies:
- thresholds to simplify continuous data;
- the best subset of features;
- the optimal Boolean logic to model decision-making.
The process generates all possible Boolean functions, simplifies them into concise formulas, and evaluates their performance. Unlike traditional machine learning, which adjusts coefficients, HKMs explore different combinations of features and rules to find the most effective yet human-comprehensible models.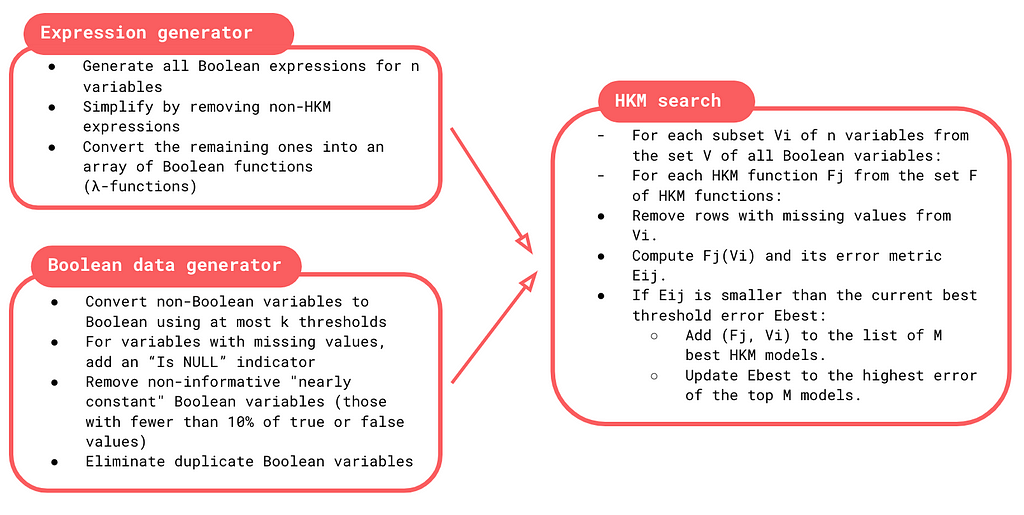
HKM training avoids imputing missing data, treating it as valuable information, and produces multiple top-performing models, giving users flexibility in choosing the most practical solution.
Where HKMs Fall Short
HKMs aren’t suited for every problem. For tasks with high branching complexity (big number of features) their simplicity becomes a disadvantage. These scenarios require substantial memory and logic that exceed human processing capacity. Nonetheless, HKMs can still play a critical role in applied fields like healthcare, where they serve as a practical starting point to address obvious blind spots.
Another limitation lies in feature identification. Unlike deep-learning models that can automatically extract complex patterns, HKMs depend on humans to define and measure key features. That’s why feature engineering falls on the shoulders of the analyst.
Churn prediction example
As a toy example we will use a generated Churn prediction dataset.
Install the libraries:
!pip install git+https://github.com/EgorDudyrev/PeaViner
!pip install bitarray
Dataset generation:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
np.random.seed(42)
n_rows = 1500
charge_amount = np.random.normal(10, np.sqrt(2), n_rows).astype(int)
seconds_of_use = np.random.gamma(shape=2, scale=2500, size=n_rows).astype(int)
frequency_of_use = np.random.normal(20, np.sqrt(10), n_rows).astype(int)
tariff_plan = np.random.choice([1, 2], size=n_rows)
status = np.random.choice([2, 3], size=n_rows)
age = np.random.randint(20, 71, size=n_rows)
noise = np.random.uniform(0, 1, n_rows)
churn = np.where(
((seconds_of_use <= 1000) & (age >= 30)) | (frequency_of_use < 16) | (noise < 0.1),
1,
0
)
df = pd.DataFrame({
"Charge Amount": charge_amount,
"Seconds of Use": seconds_of_use,
"Frequency of use": frequency_of_use,
"Tariff Plan": tariff_plan,
"Status": status,
"Age": age,
"Churn": churn
})
The dataset contains some basic metrics on user characteristics and the binary target — Churn. Sample data: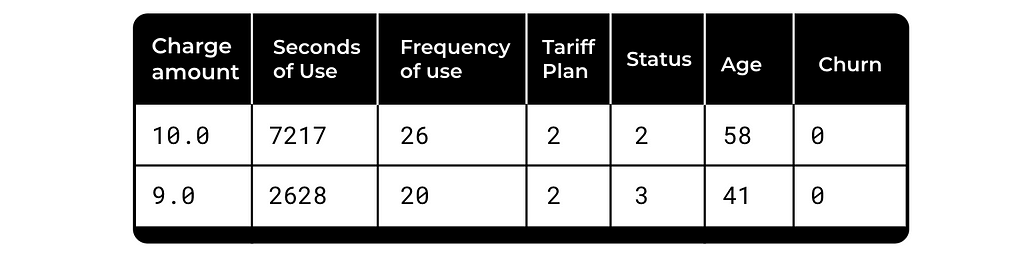
Split the dataset into train and test groups:
X = df.drop(columns=['Churn'])
y = df.Churn
X, y = X.values.astype(float), y.values.astype(int)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=42)
print(f"Train size: {len(X_train)}; Test size: {len(X_test)}")
Train size: 1200; Test size: 300
Finally we may apply the model and check the quality:
from peaviner import PeaClassifier
model = PeaClassifier()
model.fit(X_train, y_train)
model_scores = f1_score(y_train, model.predict(X_train)),
f1_score(y_test, model.predict(X_test))
print(f"Train F1 score: {model_scores[0]:.2f},
Test F1 score: {model_scores[1]:.2f}")
Train F1 score: 0.78, Test F1 score: 0.77
The results are pretty stable, training process took 3 minutes.
Now, we may check the rule, found by the model:
features = [f for f in df if f!='Churn']
model.explain(features)
(Age >= 30 AND Seconds of Use < 1010) OR Frequency of use < 16
Pretty straightforward and interpretable. Just 3 rules, no need to make inference using the model, you need just apply this simple rule to split the users. And as you see it’s almost identical to theoretical rule of data generation.
Now we’d like to compare the performance of the model with several other popular algorithms. We’ve chosen Decision Tree and XGBoost to compare 3 models of different level of complexity.
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
from sklearn.metrics import f1_score
import pandas as pd
kf = KFold(n_splits=5, random_state=42, shuffle=True)
def evaluate_model(model, X, y, get_leaves):
scores_cv, leaves = [], []
for train_idx, test_idx in kf.split(X, y):
model.fit(X[train_idx], y[train_idx])
scores_cv.append((
f1_score(y[train_idx], model.predict(X[train_idx])),
f1_score(y[test_idx], model.predict(X[test_idx]))
))
leaves.append(get_leaves(model))
return scores_cv, leaves
models = [
("XGBoost", XGBClassifier(), lambda m: (m.get_booster().trees_to_dataframe()['Feature'] == 'Leaf').sum()),
("Decision Tree", DecisionTreeClassifier(), lambda m: m.get_n_leaves()),
("Human Knowledge Model", PeaClassifier(), lambda m: 1),
]
models_data = []
for model_name, model, get_leaves in models:
scores_cv, leaves = evaluate_model(model, X, y, get_leaves)
models_data.extend({
'Model': model_name,
'Fold': fold_id,
'Train F1': train,
'Test F1': test,
'Leaves': n_leaves
} for fold_id, ((train, test), n_leaves) in enumerate(zip(scores_cv, leaves)))
models_data = pd.DataFrame(models_data)
The results for fold 0: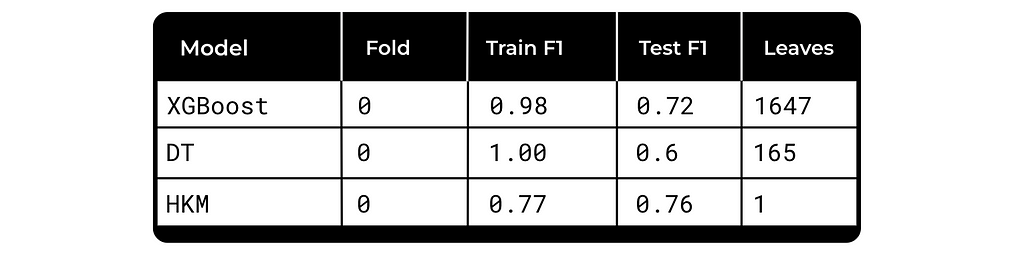
As you see, the Human Knowledge Model used just 1 rule, Decision Tree — 165 and XGBoost — 1647, but the quality on the Test group is comparable.
Now we want to visualize the quality results for all folds:
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = [10, 6]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
plt.rcParams['font.family'] = 'monospace'
plt.rcParams['font.size'] = 10
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
plt.figure(figsize=(8, 5))
for ds_part, color in zip(['Train', 'Test'], ['black', '#f95d5f']):
y_axis = f'{ds_part} F1'
plt.scatter(models_data[y_axis], 1/models_data['Leaves'], label=ds_part, alpha=0.3, s=200, color=color)
avgs = models_data.groupby('Model')['Leaves'].mean().sort_values()
avg_f1 = models_data.groupby('Model')['Test F1'].mean()
# Add vertical lines
for model_name, n_leaves in avgs.items():
plt.axhline(1/n_leaves, zorder=0, linestyle='--', color='gray', alpha=0.5, linewidth=0.6)
plt.text(0.05, 1/n_leaves*1.1, model_name)
plt.xlabel('F1 score')
plt.ylabel('1 / Number of rules')
plt.yscale('log')
plt.ylim(0, 3)
plt.xlim(0, 1.05)
# Removing top and right borders
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.show()
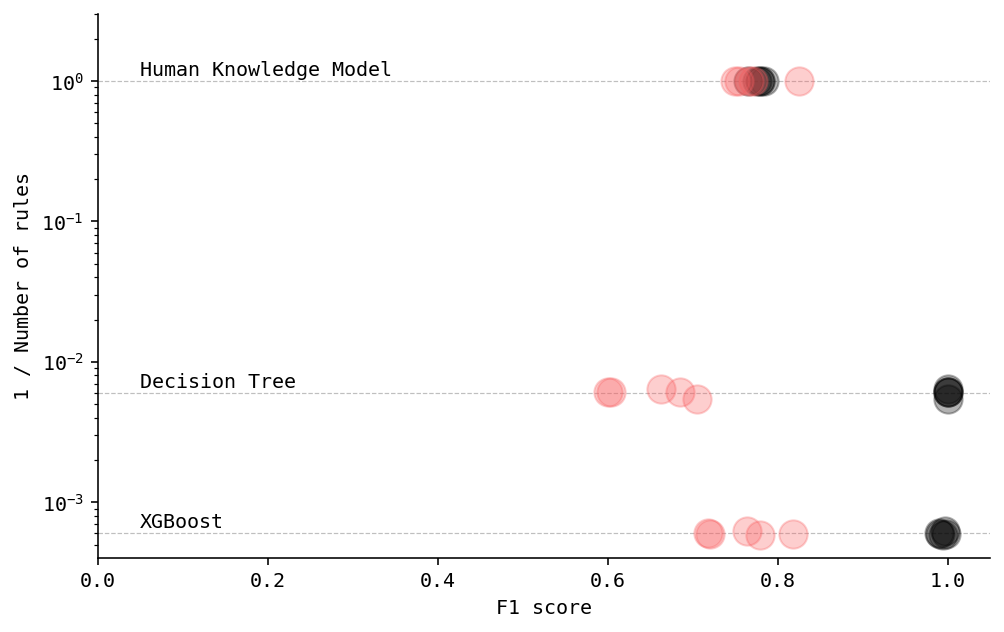
As you see, the quality of HKM on the Test subset is event better than more complex models have. Obviously, that’s because the dataset is comparably small and feature dependencies are not that complex. Anyway the rules generated by HKM may be easily used for some personalisation offer on the website. You don’t need any ML infrastructure—the rules may be incorporated even on the front end.
Conclusion
Human Knowledge Models present a novel and practical approach to integrating human-centric logic with AI, bridging the gap between explainability and performance. They achieve several key objectives:
- Simplifying Complexity: reduce complex Boolean expressions to their simplest forms;
- Enhancing Explainable AI: Unlike traditional “interpretable” AI, it focuses on active human decision-making, offering a more precise and functional definition;
- Challenging Black-Box Models: it provides an alternative to classical machine learning models, expanding AI into domains where black-box solutions are unacceptable.
References
- Cowan N., “The magical number 4 in short-term memory: A reconsideration of mental storage capacity,” The Behavioral and brain sciences, vol. 24, no. 1, pp. 87–114, 2001.
- Taniguchi H., Sato H. and Shirakawa T., “A machine learning model with human cognitive biases capable of learning from small and biased datasets,” Scientific reports, 2018–05–09, Vol.8 (1), p., vol. 8, no. 1, pp. 7397–13, 2018.
- E. Dudyrev, I. Semenkov, S. O. Kuznetsov, G. Gusev, A. Sharp, and O. S. Pianykh. Human knowledge models: Learning applied knowledge from the data. Plos one, 17(10):e0275814, 2022.
- E. Dudyrev and S. O. Kuznetsov. Towards fast finding optimal short classifiers. CEUR Workshop Proceedings, 3233:23–34, 2022.
Simplicity Over Black Boxes was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
What's Your Reaction?













