





































How to Evaluate LLM Summarization
A practical and effective guide for evaluating AI summariesImage from UnsplashSummarization is one of the most practical and convenient tasks enabled by LLMs. However, compared to other LLM tasks like question-asking or classification, evaluating LLMs on summarization is far more challenging.And so I myself have neglected evals for summarization, even though two apps I’ve built rely heavily on summarization (Podsmart summarizes podcasts, while aiRead creates personalized PDF summaries based on your highlights)But recently, I’ve been persuaded — thanks to insightful posts from thought leaders in the AI industry — of the critical role of evals in systematically assessing and improving LLM systems. (link and link). This motivated me to start investigating evals for summaries.So in this article, I will talk about an easy-to-implement, research-backed and quantitative framework to evaluate summaries, which improves on the Summarization metric in the DeepEval framework created by Confident AI.I will illustrate my process with an example notebook (code in Github), attempting to evaluate a ~500-word summary of a ~2500-word article Securing the AGI Laurel: Export Controls, the Compute Gap, and China’s Counterstrategy (found here, published in December 2024).Table of Contents∘ Why it’s difficult to evaluate summarization ∘ What makes a good summary ∘ Introduction to DeepEval ∘ DeepEval’s Summarization Metric ∘ Improving the Summarization Metric ∘ Conciseness Metrics ∘ Coherence Metric ∘ Putting it all together ∘ Future WorkWhy it’s difficult to evaluate summarizationBefore I start, let me elaborate on why I claim that summarization is a difficult task to evaluate.Firstly, the output of a summary is inherently open-ended (as opposed to tasks like classification or entity extraction). So, what makes a summary good depends on qualitative metrics such as fluency, coherence and consistency, which are not straightforward to measure quantitatively. Furthermore, these metrics are often subjective — for example, relevance depends on the context and audience.Secondly, it is difficult to create gold-labelled datasets to evaluate your system’s summaries against. For RAG, it is straightforward to create a dataset of synthetic question-answer pairs to evaluate the retriever (see this nice walkthrough).For summarization, there isn’t an obvious way to generate reference summaries automatically, so we have to turn to humans to create them. While researchers have curated summarization datasets, these would not be customized to your use case.Thirdly, I find that most summarization metrics in the academic literature are not suitable for practical-oriented AI developers to implement. Some papers trained neural summarization metrics (e.g. Seahorse, Summac etc.), which are several GBs big and challenging to run at scale (perhaps I’m just lazy and should learn how to run HuggingFace models locally and on a GPU cluster, but still it’s a barrier to entry for most). Other traditional metrics such as BLEU and ROUGE rely on exact word/phrase overlap and were created in the pre-LLM era for extractive summarization, and may not work well for evaluating abstractive summaries generated by LLMs, which could paraphrase the source text.Nevertheless, in my experience, humans can easily distinguish a good summary from a bad one. One common failure mode is being vague and roundabout-y (e.g. ‘this summary describes the reasons for…’).What makes a good summarySo what is a good summary? Eugene Yan’s article offers good detail on various summary metrics. For me, I will distil them into 4 key qualities:Relevant — the summary retains important points and details from the source textConcise — the summary is information-dense, does not repeat the same point multiple times, and is not unnecessarily verboseCoherent — the summary is well-structured and easy to follow, not just a jumble of condensed factsFaithful — the summary does not hallucinate information that is not supported by the source textOne key insight is that you can actually formulate the first two as a precision and recall problem — how many facts from the source text are retained in the summary (recall), and how many facts from the summary are supported by the main text (precision).This formulation brings us back to more familiar territory of classification problems in ML, and suggests a quantitative way to evaluate summaries.Some differences here are: firstly, a higher recall is better, holding summary length constant. You don’t want to score 100% recall with a summary the same length as the source. Secondly, you’d ideally want precision to be close to 100% as possible — hallucinating information is really bad. I’ll come back to these later.Introduction to DeepEvalYou’d be spoilt for choice with all the different LLM eval frameworks out there — from Braintrust to Langfuse and more. However, today I’ll be using DeepEval, a very user-friendly framework to get started quickly, both in general, as well a

A practical and effective guide for evaluating AI summaries
Summarization is one of the most practical and convenient tasks enabled by LLMs. However, compared to other LLM tasks like question-asking or classification, evaluating LLMs on summarization is far more challenging.
And so I myself have neglected evals for summarization, even though two apps I’ve built rely heavily on summarization (Podsmart summarizes podcasts, while aiRead creates personalized PDF summaries based on your highlights)
But recently, I’ve been persuaded — thanks to insightful posts from thought leaders in the AI industry — of the critical role of evals in systematically assessing and improving LLM systems. (link and link). This motivated me to start investigating evals for summaries.
So in this article, I will talk about an easy-to-implement, research-backed and quantitative framework to evaluate summaries, which improves on the Summarization metric in the DeepEval framework created by Confident AI.
I will illustrate my process with an example notebook (code in Github), attempting to evaluate a ~500-word summary of a ~2500-word article Securing the AGI Laurel: Export Controls, the Compute Gap, and China’s Counterstrategy (found here, published in December 2024).
Table of Contents
∘ Why it’s difficult to evaluate summarization
∘ What makes a good summary
∘ Introduction to DeepEval
∘ DeepEval’s Summarization Metric
∘ Improving the Summarization Metric
∘ Conciseness Metrics
∘ Coherence Metric
∘ Putting it all together
∘ Future Work
Why it’s difficult to evaluate summarization
Before I start, let me elaborate on why I claim that summarization is a difficult task to evaluate.
Firstly, the output of a summary is inherently open-ended (as opposed to tasks like classification or entity extraction). So, what makes a summary good depends on qualitative metrics such as fluency, coherence and consistency, which are not straightforward to measure quantitatively. Furthermore, these metrics are often subjective — for example, relevance depends on the context and audience.
Secondly, it is difficult to create gold-labelled datasets to evaluate your system’s summaries against. For RAG, it is straightforward to create a dataset of synthetic question-answer pairs to evaluate the retriever (see this nice walkthrough).
For summarization, there isn’t an obvious way to generate reference summaries automatically, so we have to turn to humans to create them. While researchers have curated summarization datasets, these would not be customized to your use case.
Thirdly, I find that most summarization metrics in the academic literature are not suitable for practical-oriented AI developers to implement. Some papers trained neural summarization metrics (e.g. Seahorse, Summac etc.), which are several GBs big and challenging to run at scale (perhaps I’m just lazy and should learn how to run HuggingFace models locally and on a GPU cluster, but still it’s a barrier to entry for most). Other traditional metrics such as BLEU and ROUGE rely on exact word/phrase overlap and were created in the pre-LLM era for extractive summarization, and may not work well for evaluating abstractive summaries generated by LLMs, which could paraphrase the source text.
Nevertheless, in my experience, humans can easily distinguish a good summary from a bad one. One common failure mode is being vague and roundabout-y (e.g. ‘this summary describes the reasons for…’).
What makes a good summary
So what is a good summary? Eugene Yan’s article offers good detail on various summary metrics. For me, I will distil them into 4 key qualities:
- Relevant — the summary retains important points and details from the source text
- Concise — the summary is information-dense, does not repeat the same point multiple times, and is not unnecessarily verbose
- Coherent — the summary is well-structured and easy to follow, not just a jumble of condensed facts
- Faithful — the summary does not hallucinate information that is not supported by the source text
One key insight is that you can actually formulate the first two as a precision and recall problem — how many facts from the source text are retained in the summary (recall), and how many facts from the summary are supported by the main text (precision).
This formulation brings us back to more familiar territory of classification problems in ML, and suggests a quantitative way to evaluate summaries.
Some differences here are: firstly, a higher recall is better, holding summary length constant. You don’t want to score 100% recall with a summary the same length as the source. Secondly, you’d ideally want precision to be close to 100% as possible — hallucinating information is really bad. I’ll come back to these later.
Introduction to DeepEval
You’d be spoilt for choice with all the different LLM eval frameworks out there — from Braintrust to Langfuse and more. However, today I’ll be using DeepEval, a very user-friendly framework to get started quickly, both in general, as well as specifically with summarization.
DeepEval has easy out-of-the-box implementations of many key RAG metrics, and it has a flexible Chain-of-Thought-based LLM-as-a-judge tool called GEval for you too define any custom criteria you want (I’ll use this later)
Additionally, it has helpful infrastructure to organize and speed up evals: they’ve nicely parallelized everything with async and so you can run evals on your entire dataset rapidly. They have handy features for synthetic data generation (will cover in later articles), and they allow you to define custom metrics to adapt their metrics (exactly what we’re going to do today), or to define non-LLM-based eval metrics for more cost-effective & robust evals (e.g. entity density, later).
DeepEval’s Summarization Metric
DeepEval’s summarization metric (read more about it here ) is a reference-free metric (i.e. no need for gold-standard summaries), and just requires the source text (that you put as input field) and the generated summary to be evaluated (actual_output) field. As you can see, the set-up and evaluation code below is really simple!
# Create a DeepEval test case for the purposes of the evaluation
test_case = LLMTestCase(
input = text,
actual_output = summary
)
# Instantiate the summarization metric
summarization_metric = SummarizationMetric(verbose_mode = True, n = 20, truths_extraction_limit = 20)
# Run the evaluation on the test case
eval_result = evaluate([test_case], [summarization_metric])
The summarization metric actually evaluates two separate components under-the-hood: alignment and coverage. These correspond closely to the precision and recall formulation I introduced earlier!
For alignment, the evaluator LLM generates a list of claims from the summary, and for each claim, the LLM will determine how many of these claims are supported by truths which are extracted from the source text, producing the alignment score.
In the case of coverage, the LLM generates a list of assessment questions from the source text, then tries to answer the questions, using only the summary as context. The LLM is prompted to respond ‘idk’ if the answer cannot be found. Then, the LLM will determine how many of these answers are correct, to get the coverage score.
The final summarization score is the minimum of the alignment and coverage scores.
Improving the Summarization Metric
However, while what DeepEval has done is a great starting point, there are three key issues that hinder the reliability and usefulness of the Summarization metric in its current form.
So I have built a custom summarization metric which adapts DeepEval’s version. Below, I’ll explain each problem and the corresponding solution I’ve implemented to overcome it:
1: Using yes/no questions for the coverage metric is too simplistic
Currently, the assessment questions are constrained to be yes/no questions, in which the answer to the question is yes — have a look at the questions: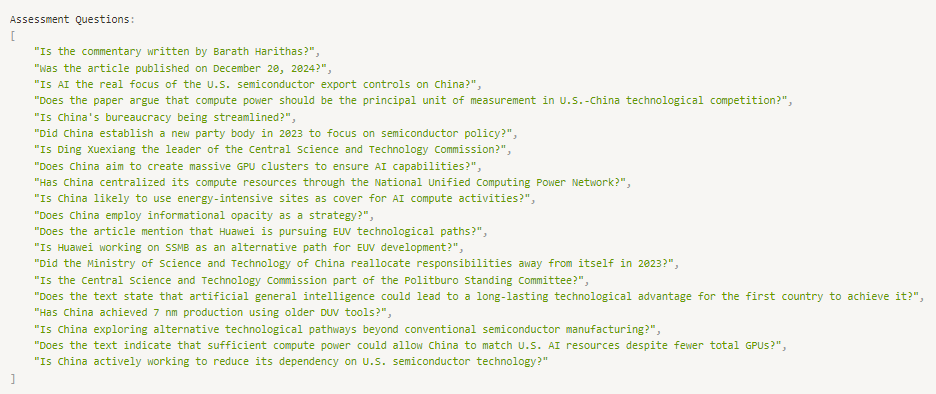
There are two problems with this:
Firstly, by framing the questions as binary yes/no, this limits their informativeness, especially in determining nuanced qualitative points.
Secondly, if the LLM that answers given the summary hallucinates a ‘yes’ answer (as there are only 3 possible answers: ‘yes’, ‘no’, ‘idk’, it’s not unlikely it’ll hallucinate yes), the evaluator will erroneously deem this answer to be correct. It is much more difficult to hallucinate the correct answer to an open-ended question. Furthermore, if you look at the questions, they are phrased in a contrived way almost hinting that the answer is ‘yes’ (e.g. “Does China employ informational opacity as a strategy?”), hence increasing the likelihood of a hallucinated ‘yes’.
My solution was to ask the LLM generate open-ended questions from the source text — in the code, these are referred to as ‘complex questions’.
Additionally, I ask the LLM to assign an importance of the question (so we can perhaps upweight more important questions in the coverage score).
Since the questions are now open-ended, I use an LLM for evaluation — I ask the LLM to give a 0–5 score of how similar the answer generated from the summary is to the answer generated with the source text (the reference answer), as well as an explanation.
def generate_complex_verdicts(answers):
return f"""You are given a list of JSON objects. Each contains 'original_answer' and 'summary_answer'.
Original answer is the correct answer to a question.
Your job is to assess if the summary answer is correct, based on the model answer which is the original answer.
Give a score from 0 to 5, with 0 being completely wrong, and 5 being completely correct.
If the 'summary_answer' is 'idk', return a score of 0.
Return a JSON object with the key 'verdicts', which is a list of JSON objects, with the keys: 'score', and 'reason': a concise 1 sentence explanation for the score.
..."""
def generate_complex_questions(text, n):
return f"""Based on the given text, generate a list of {n} questions that can be answered with the information in this document.
The questions should be related to the main points of this document.
Then, provide a concise 1 sentence answer to the question, using only information that can be found in the document.
Answer concisely, your answer does not need to be in full sentences.
Make sure the questions are different from each other.
They should cover a combination of questions on cause, impact, policy, advantages/disadvantages, etc.
Lastly, rate the importance of this question to the document on a scale of 1 to 5, with 1 being not important and 5 being most important.
Important question means the question is related to an essential or main point of the document,
and that not knowing the answer to this question would mean that the reader has not understood the document's main point at all.
A less important question is one asking about a smaller detail, that is not essential to understanding the document's main point.
..."""
2: Extracting truths from source text for alignment is flawed
Currently, for the alignment metric, a list of truths is extracted from the source text using an LLM (a parameter truths_extraction_limit which can be controlled). This leads to some facts/details from the source text being omitted from the truths, which the summary’s claims are then compared against.
To be honest, I’m not sure what the team was thinking when they implemented it like this — perhaps I had missed a nuance or misunderstood their intention.
However, this leads to two problems that renders the alignment score ‘unusable’ according to a user on Github.
Firstly, the LLM-generated list of truths is non-deterministic, hence people have reported wildly changing alignment scores. This inconsistency likely stems from the LLM choosing different subsets of truths each time. More critically, the truth extraction process makes this not a fair judge of the summary’s faithfulness, because a detail from the summary could possibly be found in the source text but not the extracted truths. Anecdotally, all the claims that were detected as unfaithful, indeed were in the main text but not in the extracted truths. Additionally, people have reported that when you pass in the summary as equal to input, the alignment score is less than 1, which is strange.
To address this, I just made a simple adjustment — which was to pass the entire source text into the LLM evaluating the summary claims, instead of the list of truths. Since all the claims are evaluated together in one LLM call, this won’t significantly raise token costs.
3: Final score being min(alignment score, coverage score) is flawed
Currently, the score that is output is the minimum of the alignment and coverage scores (and there’s actually no way of accessing the individual scores without placing it in the logs).
This is problematic, because the coverage score will likely be lower than the alignment score (if not, then there’re real problems!). This means that changes in the alignment score do not affect the final score. However, that doesn’t mean that we can ignore deteriorations in the alignment score (say from 1 to 0.8), which are arguably signal a more severe problem with the summary (i.e. hallucinating a claim).
My solution was to change the final score to the F1 score, just like in ML classification, to capture importance of both precision and recall. An extension is to can change the weighting of precision & recall. (e.g. upweight precision if you think that hallucination is something to avoid at all costs — see here)
With these 3 changes, the summarization metric now better reflects the relevance and faithfulness of the generated summaries.
Conciseness Metrics
However, this still gives an incomplete picture. A summary should also concise and information-dense, condensing key information into a shorter version.
Entity density is a useful and cheap metric to look at. The Chain-of-Density paper shows that human-created summaries, as well as human-preferred AI-generated summaries, have an entity density of ~0.15 entities/tokens, striking the right balance between clarity (favoring less dense) and informativeness (favoring more dense).
Hence, we can create a Density Score which penalizes summaries with Entity Density further away from 0.15 (either too dense or not dense enough). Initial AI-generated summaries are typically less dense (0.10 or less), and the Chain-of-Density paper shows an iterative process to increase the density of summaries. Ivan Leo & Jason Liu wrote a good article on fine-tuning Chain-of-Density summaries using entity density as the key metric.
import nltk
import spacy
nlp = spacy.load("en_core_web_sm")
def get_entity_density(text):
summary_tokens = nltk.word_tokenize(text)
num_tokens = len(summary_tokens)
# Extract entities
doc = nlp(text)
num_entities = len(doc.ents)
entity_density = num_entities / num_tokens
return entity_density
Next, I use a Sentence Vagueness metric to explicitly penalize vague sentences ( ‘this summary describes the reasons for…’) that don’t actually state the key information.
For this, I break up the summary into sentences (similar to the alignment metric) and ask an LLM to classify if each sentence is vague or not, with the final score being the proportion of sentences classified as vague.
prompt = ChatPromptTemplate.from_template(
"""You are given a list of sentences from a summary of a text.
For each sentence, your job is to evaluate if the sentence is vague, and hence does not help in summarizing the key points of the text.
Vague sentences are those that do not directly mention a main point, e.g. 'this summary describes the reasons for China's AI policy'.
Such a sentence does not mention the specific reasons, and is vague and uninformative.
Sentences that use phrases such as 'the article suggests', 'the author describes', 'the text discusses' are also considered vague and verbose.
...
OUTPUT:"""
)
class SentenceVagueness(BaseModel):
sentence_id: int
is_vague: bool
reason: str
class SentencesVagueness(BaseModel):
sentences: List[SentenceVagueness]
chain = prompt | llm.with_structured_output(SentencesVagueness)
Lastly, a summary that repeats the same information is inefficient, as it wastes valuable space that could have been used to convey new meaningful insights.
Hence, we construct a Repetitiveness score using GEval. As I briefly mentioned above, GEval uses LLM-as-a-judge with chain-of-thoughts to evaluate any custom criteria. As detecting repeated concepts is a more complex problem, we need a more intelligent detector aka an LLM. (Warning: the results for this metric seemed quite unstable — the LLM would change its answer when I ran it repeatedly on the same input. Perhaps try some prompt engineering)
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams
repetitiveness_metric = GEval(
name="Repetitiveness",
criteria="""I do not want my summary to contain unnecessary repetitive information.
Return 1 if the summary does not contain unnecessarily repetitive information, and 0 if the summary contains unnecessary repetitive information.
facts or main points that are repeated more than once. Points on the same topic, but talking about different aspects, are OK. In your reasoning, point out any unnecessarily repetitive points.""",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
verbose_mode = True
)
Coherence Metric
Finally, we want to ensure that LLM outputs are coherent — having a logical flow with related points together and making smooth transitions. Meta’s recent Large Concept Models paper used this metric for local coherence from Parola et al (2023) — the average cosine similarity between each nth and n+2th sentence. A simple metric that is easily implemented. We find that the LLM summary has a score of ~0.45. As a sense check, if we randomly permute the sentences of the summary, the coherence score drops below 0.4.
# Calculate cosine similarity between each nth and n+2th sentence
def compute_coherence_score(sentences):
embedding_model = OpenAIEmbeddings(model="text-embedding-3-small")
sentences_embeddings = embedding_model.embed_documents(sentences)
sentence_similarities = []
for i in range(len(sentences_embeddings) - 2):
# Convert embeddings to numpy arrays and reshape to 2D
emb1 = np.array(sentences_embeddings[i])
emb2 = np.array(sentences_embeddings[i+2])
# Calculate cosine distance
distance = cosine(emb1, emb2)
similarity = 1 - distance
sentence_similarities.append(similarity)
coherence_score = np.mean(sentence_similarities)
return coherence_score
Putting it all together
We can package each of the above metrics into Custom Metrics. The benefit is that we can evaluate all of them in parallel on your dataset of summaries and get all your results in one place! (see the code notebook)
One caveat, though, is that for some of these metrics, like Coherence or Recall, there isn’t a sense of what the ‘optimal’ value is for a summary, and we can only compare scores across different AI-generated summaries to determine better or worse.
Future Work
What I’ve introduced in this article provides a solid starting point for evaluating your summaries!
It’s not perfect though, and there areas for future exploration and improvement.
One area is to better test whether the summaries capture important points from the source text. You don’t want a summary that has a high recall, but of unimportant details.
Currently, when we generate assessment questions, we ask LLM to rate their importance. However, it’s hard to take those importance ratings as the ground-truth either — if you think about it, when LLMs summarize they essentially rate the importance of different facts too. Hence, we need a measure of importance outside the LLM. Of course, the ideal is to have human reference summaries, but these are expensive and not scalable. Another source of reference summaries would be reports with executive summaries (e.g. finance pitches, conclusion from slide decks, abstract from papers). We could also use techniques like the PageRank of embeddings to identify the central concepts algorithmically.
An interesting idea to try is generating synthetic source articles — start with a set of main points (representing ground-truth “important” points) on a given topic, and then ask the LLM lengthen into a full article (run this multiple times with high temperature to generate many diverse synthetic articles!). Then run the full articles through the summarization process, and evaluate the summaries on retaining the original main points.
Last but not least, it is very important to ensure that each of the summarization metrics I’ve introduced correlates with human evaluations of summary preference. While researchers have done so for some metrics on large summarization datasets, these findings might not generalize to your texts and/or audience. (perhaps your company prefers a specific style of summaries e.g. with many statistics).
For an excellent discussion on this topic, see ‘Level 2’ of Hamel Husain’s article on evals. For example, if you find that LLM’s Sentence Vagueness scores don’t correlate well with what you consider to be vague sentences, then some prompt engineering (providing examples of vague sentences, elaborating more) can hopefully bring the correlation up.
Although this step can be time-consuming, it is essential, in order to ensure you can trust the LLM evals. This will save you time in the long run anyway — when your LLM evals are aligned, you essentially gain an infinitely-scalable evaluator customised to your needs and preferences.
You can speed up your human evaluation process by creating an easy-to-use Gradio annotation interface — I one-shotted a decent interface using OpenAI o1!
In a future article, I will talk about how to actually use these insights to improve my summarization process. Two years ago I wrote about how to summarize long texts, but both LLM advances and 2 years of experience have led to my summarization methods changing dramatically.
Thanks so much for reading! In case you missed it, all the code can be found in the GitHub repo here. What metrics do you use to evaluate LLM summarization? Let me know in the comments!
How to Evaluate LLM Summarization was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
What's Your Reaction?













